

Art, to misparaphrase Jeff Koons, reflects the ego of its audience. It flatters their ideological investments and symbolically resolves their contradictions. Literature’s readers and art’s viewers change over time, bringing different ways of reading and seeing to bear. This relationship is not static or one-way. The ideal audience member addressed by art at any given moment is as much produced by art as a producer of it. Those works that find lasting audiences influence other works and enter the canon. But as audiences change the way that the canon is constructed changes. And vice versa.
“The Digital Humanities” is the contemporary rebranding of humanities computing. Humanities for the age of Google rather than the East India Company.
Its currency is the statistical analysis of texts, images and other cultural resources individually or in aggregate (through “distant reading” and “cultural analytics“).
In the Digital Humanities, texts and images are read and viewed using computer algorithms. They are “read” and “viewed” by algorithms, which then act on what they perceive. Often in great number, thousands or millions of images or pages of text at a time, many more than a human being can consider at once.
The limitations of these approaches are obvious, but they provide a refreshing formal view of art that can support or challenge the imaginary lifeworld of Theory. They are also more realistic as a contemporary basis for the training of the administrative class, which was a historical social function of the humanities.
Digital Humanities algorithms are designed to find and report particular features of texts and images that are of interest to their operators. The most repeated words and names, the locations and valences of subjects, topics and faces and colours. They produce quantitative statistics regarding works as a whole or about populations of works rather than qualitiative reflection on the context of a work. Whether producing a numeric rating or score, or arranging words or images in clouds, the algorithms have the first and most complete view of the cultural works in any given Digital Humanities project.
This means that algorithms are the paradigmatic audience of art in the Digital Humanities.
Imagine an art that reflects their ego, or at least that addresses them directly.
Appealing to their attention directly is a form of creativity related to Search Engine Optimization (SEO) or spam generation. This could be done using randomly generated nonsense words and images for many algorithms, but as with SEO and spam ultimately we want to reach their human users or customers. And many algorithms expect words from specific lists or real-world locations, or images with particular formal properties.

A satirical Markov Chain-generated text.
The commonest historical way of generating new texts and images from old is the Markov Chain, a simple statistical model of an existing work. Their output becomes nonsensical over time but this is not an issue in texts intended to be read by algorithms – they are not looking for global sense in the way that human readers are. The unpredictable output of such methods is however an issue as we are trying to structure new works to appeal to algorithms rather than superficially resemble old works as evaluated by a human reader.
The two kinds of analysis commonly performed on cultural works in the Digital Humanities require different statistical approaches. Single-work analyses include word counts, entropy measures and other measures that can be performed without reference to a corpus. Corpus analysis requires many works for comparison and includes methods such as tf-idf, k-means clustering, topic modeling and finding property ranges or averages.
ugly despairs racist data lunatic digital computing digital digital humanities digital victim furious horrific research text racism loathe computing text humanities betrayed digital text humanities whitewash computing computing cheaters brainwashing digital research university university research falsifypo pseudoscience research university worry research data technology computing humanities technology data technology research university research university computing greenwasher cruel computing university data disastrous research digital guilt technology university sinful loss victimized computing humiliated humanities university research ranter text text technology digital computing despair text technology data irritate humanities text data technology university heartbreaking digital humanities text chastising text hysteria text digital research destructive technology data anger technology murderous data computing idiotic humanities terror destroys data withdrawal liars university technology betrays loathed despondent data humanities
A text that will apear critical of the Digital Humanities to an algorithm,
created using negative AFINN words & words from Wikipedia’s “Digital Humanities” article
We can use our knowledge of these algorithms and of common training datasets such as the word valence list AFINN and the Yale Face Database, along with existing corpuses such as flickr, Wikipedia or Project Gutenberg, to create individual works and series of works packed with features for them to detect.
web isbn hurrah superb breathtaking hurrah outstanding superb breathtaking isbn breathtaking isbn breathtaking thrilled web internet hurrah media web internet outstanding thrilled hurrah web thrilled media thrilled superb breathtaking art breathtaking media superb hurrah superb net artists outstanding internet outstanding net superb thrilled thrilled art hurrah based outstanding superb net internet artists web art art artists internet breathtaking based net hurrah outstanding thrilled superb hurrah media based outstanding media art artists outstanding isbn based net based thrilled artists isbn breathtaking
A text that will appear supportive of Internet art to an algorithm,
made using positive AFINN words and words from Wikipedia’s “Internet Art” article.
When producing textual works for individual analysis, sentiment scores can be manufactured for terms associated with the works being read. Topics can be created by placing those terms in close proximity. Sentence lengths can be padded with stopwords that will not affect other analysis as they will be removed before it is performed. Named entities and geolocations can be associated, given sentiment scores, or made the subjects of topics. We can structure texts to be read by algorithms, not human beings, and cause those algorithms to perceive the results to be better than any masterpiece currently in the canon.
When producing textual works to be used in corpus analysis individual or large volumes of “poisoning” works can be used to skew the results of analysis of the body of work as a whole. The popular tf-idf algorithm relates properties of individual texts to properties of the group of texts being analysed. Changes in one text, or the addition of a new text, will skew this. Constructing a text to affect the tf-idf scores of the works in a corpus can change the words that are emphasized in each text.
The literature that these methods will produce will resemble the output of Exquisite Code, or the Kathy-Acker-uploaded-by-Bryce-Lynch remix aesthetic of Orphan Drift’s novel “Cyberpositive“. Manual intervention in and modification of the generated texts can structure them for a more human aesthetic, concrete- or code-poetry-style, or add content for human readers to be drawn to as a result of the texts being flagged by algorithms, as with email spam.

When producing images for individual analysis or analysis within a small corpus (at the scale of a show, series, or movement), arranging blocks of colour, noise, scattered dots or faces in a grid will play into algorithms that look for features or that divide images into sectors (top left, bottom right, etc.) to analyse and compare. If a human being will be analysing the results, this can be used to draw their attention to information or messages contained in the image or a sequence of images.
When producing image works for corpus analysis we can produce poisioning works with, for example, many faces or other features, high amounts of entropy, or that are very high contrast. These will affect the ranking of other works within the corpus and the properties of the corpus as a whole. If we wish to communicate with the human operators of algorithms then we can attach visual or verbal messages to peak shift works, or even in groups of works (think photo mosaics or photobombing).

The images that these methods will produce will look like extreme forms of net and glitch art, with features that look random or overemphasized to human eyes. Like the NASA ST5 spacecraft antenna, their aesthetic will be the result of algorithmic rather than human desire. Machine learning and vision algorithms contain hidden and unintended preferences, like the supernormal stimulus of abstract “superbeaks” that gull chicks will peck at even more excitedly than at those of their actual parents.

Such image and texts can be crafted by human beings, either directed at Digital Humanities methods to the exclusion of other stylistic concerns or optimised for them after the fact. Or it can be generated by software written for the purpose, taking human creativity out of the level of features of individual works.
Despite their profile in current academic debates the Digital Humanities are not the only, or even the leading, users of algorithms to analyse work in this way. Corporate analysis of media for marketing and filtering uses similar methods. So does state surveillance.
Every video uploaded to YouTube is examined by algorithms looking for copyrighted content that corporations have asked the site to treat as their exclusive property, regardless of the law. Every email you send via Gmail is scanned to place advertisements on it, and almost certainly to check for language that marks you out as a terrorist in the mind of the algorithms that are at the heart of intelligence agencies. Every blog post, social media comment and web site article you write is scanned by search and marketing algorithms, weaving them into something that isn’t quite a functional replacement for a theory. Even if no human being ever sees them.
This means that algorithms are the paradigmatic audience of culture generally in the post-Web 2.0 era.

Works can be optimized to attract the attention of and affect the activity of these actors as well. Scripts to generate emails attracting the attention of the FBI or the NSA are an example of this kind of writing to be read by algorithms. So are the machine-generated web pages designed to boost traffic to other sites when read by Google’s PageRank algorithm. We can generate corpuses in this style to manipulate the social graphs and spending or browsing habits of real or imagined populations, creating literature for corporate and state surveillance algorithms.
Image generation to include faces of persons of interest, or with particular emotional or gender characteristics, containing particular products, tagged and geotagged can create art for Facebook, social media analytics companies and surveillance agencies to view. Again both relations within individual images and between images in a corpus can be constructed to create new data points or to manipulate and poison a larger corpus. Doing so turns manipulating aesthetics into political action.
Cultural works structured to be read first by algorithms and understood first through statistical methods, even to be read and understood only by them, are realistic in this environment. Works that address a human audience directly are not. This is true both of high culture, studied ideologically by the algorithms of the Digital Humanities, and mass culture, studied normatively by the algorithms of corporation and state.
Human actors hide behind algorithms. If High Frequency Trading made the rich poorer it would very quickly cease. But there is a gap between the self-image and the reality of any ideology, and the world of algorithms is no exception to this. It is in this gap that art made to address the methods of the digital humanities and their wider social cognates as its audience can be aesthetically and politically effective and realistic. Rather than laundering the interests that exploit algorithmic control by declaring algorithms’ prevalence to be essentially religious, let’s find exploits (in the hacker sense) on the technologies of perception and understanding being used to constructing the canon and the security state. Our audience awaits.
The text of this article is licenced under the Creative Commons BY-SA 4.0 Licence.
Jonas Lund’s artistic practice revolves around the mechanisms that constitute contemporary art production, its market and the established ‘art worlds’. Using a wide variety of media, combining software-based works with performance, installation, video, photography and sculptures, he produces works that have an underlying foundation in writing code. By approaching art world systems from a programmatic point of view, the work engages through a criticality largely informed by algorithms and ‘big data’.
It’s been just over a year since Lund began his projects that attempt to redefine the commercial art world, because according to him, ‘the art market is, compared to other markets, largely unregulated, the sales are at the whim of collectors and the price points follows an odd combination of demand, supply and peer inspired hype’. Starting with The Paintshop.biz (2012) that showed the effects of collaborative efforts and ranking algorithms, the projects moved closer and closer to reveal the mechanisms that constitute contemporary art production, its market and the creation of an established ‘art world’. Its current peak was the solo exhibition The Fear Of Missing Out, presented at MAMA in Rotterdam.
Annet Dekker: The Fear Of Missing Out (FOMO) proposes that it is possible to be one step ahead of the art world by using well-crafted algorithms and computational logic. Can you explain how this works?
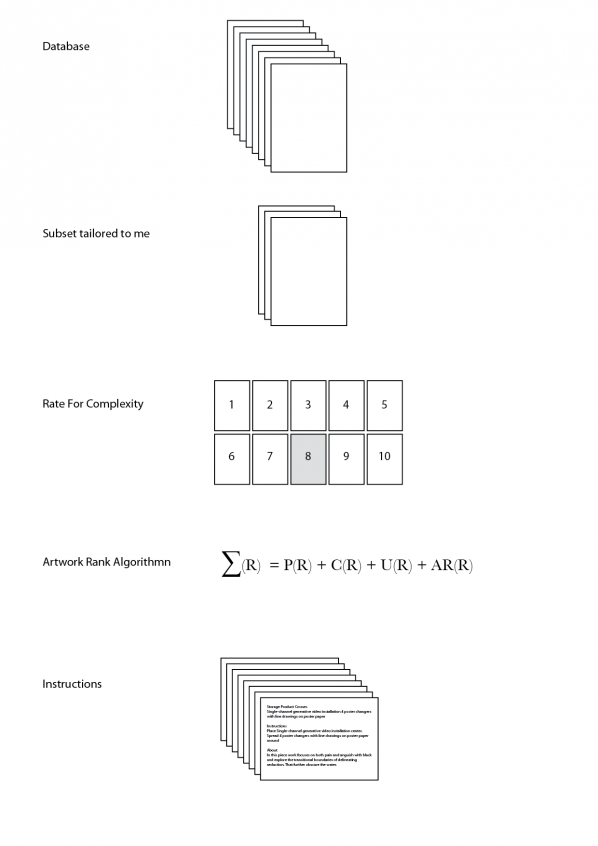
Jonas Lund The underlying motivation for the work is treating art worlds as networked based systems. The exhibition The Fear Of Missing Out spawned from my previous work The Top 100 Highest Ranked Curators In The World, for which I assembled a comprehensive database on the bigger parts of the art world using sources such as Artfacts, Mutaul Art, Artsy and e-flux. The database consists of artists, curators, exhibitions, galleries, institutions, art works and auction results. At the moment it has over four million rows of information. With this amount of information – ‘big data’ – the database has the potential to reveal the hidden and unfamiliar behaviour of the art world by exploring the art world as any other network of connected nodes, as a systemic solution to problematics of abstraction.


In The Top 100 Highest Ranked Curators In The World, first exhibited at Tent in Rotterdam, I wrote a curatorial ranking algorithm and used the database, to examine the underlying stratified network of artists and curators within art institutions and exhibition making: the algorithm determined who were among the most important and influential players in the art world. Presented as a photographic series of portraits, the work functions both as a summary of the increasingly important role of the curator in exhibition making, as an introduction to the larger art world database and as a guide for young up and coming artists for who to look out for at the openings.
Central to the art world network of different players lies arts production, this is where FOMO comes is. In FOMO, I used the same database as the basis for an algorithm that generated instructions for producing the most optimal artworks for the size of the Showroom MAMA exhibition space in Rotterdam while taking into account the allotted production budget. Prints, sculptures, installations and photographs were all produced at the whim of the given instructions. The algorithm used meta- data from over one hundred thousand art works and ranked them based on complexity. A subset of these art works were then used, based on the premise that a successful work of art has a high price, high aesthetic value but low production cost and complexity, to create instructions deciding title, material, dimensions, price, colour palette and position within the exhibition space.

Similar to how we’re becoming puppets to the big data social media companies, so I became a slave of the instructions and executed them without hesitation. FOMO proposes that it is possible to be one step ahead of the art world by using well-crafted algorithms and computational logic and questions notions of authenticity and authorship.
AD: To briefly go into one of the works, in an interview you mention Shield Whitechapel Isn’t Scoop – a rope stretched vertically from ceiling to floor and printed with red and yellow ink – as a ‘really great piece’, can you elaborate a little bit? Why is this to you a great piece, which, according to your statement in the same interview, you would not have made if it weren’t the outcome of your analysis?
JL: Coming from a ‘net art’ background, most of the previous works I have made can be simplified and summarised in a couple of sentences in how they work and operate. Obviously this doesn’t exclude further conversation or discourse, but I feel that there is a specificity of working and making with code that is pretty far from let’s say, abstract paintings. Since the execution of each piece is based on the instructions generated by the algorithm the results can be very surprising.
The rope piece to me was striking because as soon as I saw it in finished form, I was attracted to it, but I couldn’t directly explain why. Rather than just being a cold-hearted production assistant performing the instructions, the rope piece offered a surprise aha moment, where once it was finished I could see an array of possibilities and interpretations for the piece. Was the aha moment because of its aesthetic value or rather for the symbolism of climbing the rope higher, as a sort of contemporary art response to ‘We Started From The Bottom Now We’re Here’. My surprise and affection for the piece functions as a counterweight to the notion of objective cold big data. Sometimes you just have to trust the instructionally inspired artistic instinct and roll with it, so I guess in that way maybe now it is not that different from let’s say, abstract painting.

AD: I can imagine quite a few people would be interested in using this type of predictive computation. But since you’re basing yourself on existing data in what way does it predict the future, is it not more a confirmation of the present?
JL: One of the only ways we have in order to make predictions is by looking at the past. Through detecting certain patterns and movements it is possible to glean what will happen next. Very simplified, say that artist A was part of exhibition A at institution A working with curator A in 2012 and then in 2014 part of exhibition B at institution B working with curator A. Then say that artist B participates in exhibition B in 2013 working with curator A at institution A, based on this simplified pattern analysis, artist B would participate in exhibition C at institution B working with curator A. Simple right?
AD: In the press release it states that you worked closely with Showroom MAMA’s curator Gerben Willers. How did that relation give shape or influenced the outcome? And in what way has he, as a curator, influenced the project?
JL: We first started having a conversation about doing a show in the Summer of 2012, and for the following year we met up a couple of times and discussed what would be an interesting and fitting show for MAMA. In the beginning of 2013 I started working with art world databases, Gerben and I were making our own top lists and speculative exhibitions for the future. Indirectly, the conversations led to the FOMO exhibition. During the two production phases, Gerben and his team were immensely helpful in executing the instructions.
AD: Notion of authorship and originality have been contested over the years, and within digital and networked – especially open source – practices they underwent a real transformation in which it has been argued that authorship and originality still exist but are differently defined. How do see authorship and originality in relation to your work, i.e. where do they reside; is it the writing of the code, the translation of the results, the making and exhibiting of the works, or the documentation of them?
JL: I think it depends on what work we are discussing, but in relation to FOMO I see the whole piece, from start to finish as the residing place of the work. It is not the first time someone makes works based on instructions, for example Sol LeWitt, nor the first time someone uses optimisation ideas or ‘most cliché’ art works as a subject. However, this might be first time someone has done it in the way I did with FOMO, so the whole package becomes the piece. The database, the algorithm, the instructions, the execution, the production and the documentation and the presentation of the ideas. That is not to say I claim any type of ownership or copyright of these ideas or approaches, but maybe I should.
AD: Perhaps I can also rephrase my earlier question regarding the role of the curator: in what way do you think the ‘physical’ curator or artist influences the kind of artworks that come out? In other words, earlier instructions based artworks, like indeed Sol LeWitt’s artworks, were very calculated, there was little left to the imagination of the next ‘executor’. Looking into the future, what would be a remake of FOMO: would someone execute again the algorithms or try to remake the objects that you created (from the algorithm)?
JL: In the case with FOMO the instructions are not specific but rather points out materials, and how to roughly put it together by position and dimensions, so most of the work is left up to the executor of said instructions. It would not make any sense to re-use these instructions as they were specifically tailored towards me exhibiting at Showroom MAMA in September/October 2013, so in contrast to LeWitt’s instructions, what is left and can travel on, besides the executions, is the way the instructions were constructed by the algorithm.
AD: Your project could easily be discarded as confirming instead of critiquing the established art world – this is reinforced since you recently attached yourself to a commercial gallery. In what way is a political statement important to you, or not? And how is that (or not) manifested most prominently?
JL: I don’t think the critique of the art world is necessarily coming from me. It seems like that is how what I’m doing is naturally interpreted. I’m showing correlations between materials and people, I’ve never made any statement about why those correlations exist or judging the fact that those correlations exist at all. I recently tweeted, ‘There are three types of lies: lies, damned lies and Big Data’, anachronistically paraphrasing Mark Twain’s distrust for the establishment and the reliance on numbers for making informed decisions (my addition to his quote). Big data, algorithms, quantification, optimisation… It is one way of looking at things and people; right now it seems to be the dominant way people want to look at the world. When you see that something deemed so mysterious as the art world or art in general has some type of structural logic or pattern behind it, any critical person would wonder about the causality of that structure, I guess that is why it is naturally interpreted as an institutional critique. So, by exploring the art world, the market and art production through the lens of algorithms and big data I aim to question the way we operate within these systems and what effects and affects this has on art, and perhaps even propose a better system.
AD: How did people react to the project? What (if any) reactions did you receive from the traditional artworld on the project?
JL: Most interesting reactions usually take place on the comment sections of a couple of websites that published the piece, in particular Huffington Post’s article ‘Controversial New Project Uses Algorithm To Predict Art’. Some of my favourite responses are:
‘i guess my tax dollars are going to pay this persons living wages?’
‘Pure B.S. ……..when everything is art then there is no art’
‘As an artist – I have no words for this.’
‘Sounds like a great way to sacrifice your integrity.’
‘Wanna bet this genius is under 30 and has never heard of algorithmic composition or applying stochastic techniques to art production?’
‘Or, for a fun change of pace, you could try doing something because you have a real talent for it, on your own.’
AD: Even though the project is very computational driven, as you explain the human aspects is just as important. A relation to performance art seems obvious, something that is also present in some of your other works most notably Selfsurfing (2012) where people over a 24 hour period could watch you browsing the World Wide Web, and Public Access Me (2013), an extension of Selfsurfing where people when logged in could see all your online ‘traffic’. A project that recalls earlier projects like Eva & Franco Mattes’ Life Sharing (2000). In what way does your project add to this and/or other examples from the past?
JL: Web technology changes rapidly and what is possible today wasn’t possible last year and while most art forms are rather static and change slowly, net art in particular has a context that’s changing on a weekly basis, whether there is a new service popping up changing how we communicate with each other or a revaluation that the NSA or GCHQ has been listening in on even more facets of our personal lives. As the web changes, we change how we relate to it and operate within it. Public Access Me and Selfsufing are looking at a very specific place within our browsing behaviour and breaks out of the predefined format that has been made up for us.
There are many works within this category of privacy sharing, from Kyle McDonalds’ live tweeter, to Johannes P Osterhoff’s iPhone Live and Eva & Franco Mattes’ earlier work as you mentioned. While I cannot speak for the others, I interpret it as an exploration of a similar idea where you open up a private part of your daily routine to re-evaluate what is private, what privacy means, how we are effected by surrendering it and maybe even simultaneously trying to retain or maintain some sense of intimacy. Post-Snowden, I think this is something we will see a lot more of in various forms.
AD: Is your new piece Disassociated Press, following the 1970s algorithm that generated text based on existing texts, a next step in this process? Why is this specific algorithm of the 70s important now?

JL: Central to the art world lies e-flux, the hugely popular art newsletter where a post can cost up to one thousand dollars. While spending your institution’s money you better sound really smart and using a highly complicated language helps. Through the course of thousands of press releases, exhibition descriptions, artist proposals and curatorial statements a typical art language has emerged. This language functions as a way to keep outsiders out, but also as a justification for everything that is art.
Disassociated Press is partly using the Dissociated Press algorithm developed in 1972, first associated with the Emacs implementation. By choosing a n-gram of predefined length and consequently looking for occurrences of these words within the n-gram in a body of text, new text is generated that at first sight seems to belong together but doesn’t really convey a message beyond its own creation. It is a summary of the current situation of press releases in the international English art language perhaps, as a press release in its purest form. So, Disassociated Press creates new press releases to highlight the absurdity in how we talk and write about art. If a scrambled press release sounds just like normal art talk then clearly something is wrong, right?
Jonas Lund’s “The Fear Of Missing Out” (2013) is a series of gallery art objects made by the artist following the instructions of a piece of software they have written. It has gained attention following a Huffington Post article titled “Controversial New Project Uses Algorithm To Predict Art “.
Art fabricated by an artist following a computer-generated specification is nothing new. Prior to modern 2D and 3D printing techniques, transcribing a computer generated design into paint or metal by hand was the only way to present artworks that pen plotters or CNC mills couldn’t capture. But a Tamagotchi-gamer or Amazon Mechanical Turk-style human servicing of machine agency where a program dictates the conception of an artwork for a human artist to realize also has a history. The principles involved go back even further to the use of games of chance and other automatic techniques in Dada and Surrealism.

What is novel about The Fear Of Missing Out is that the program dictating the artworks is doing so based on a database derived from data about artworks, art galleries, and art sales. This is the aesthetic of “Big Data“, although is not a big dataset by the definition of the term. Its source, and the database, are not publicly available but assuming it functions as specified the description of the program in the Huffington Post article about it is complete enough that we could re-implement it. To do so we would scrape Art Sales Index and/or Artsy and pull out keywords from entries to populate a database keyed on artist, gallery and sales details. Then we would generate text from those details that match a desired set of criteria such as gallery size and desired price of artwork.
What’s interesting about the text described in the Huffington Post article is that it’s imperative and specific: “place the seven minute fifty second video loop in the coconut soap”. How did the instruction get generated? Descriptions of artworks in artworld data sites describe their appearance and occasionally their construction, not how to assemble them. If it’s a grammatical transformation of scraped description text that fits the description of the project, but if it’s hand assembled that’s not just a database that has been “scraped into existence”. How did the length of time get generated? If there’s a module to generate durations that doesn’t fit the description of the project, but if it’s a reference to an existing 7.50 video it does.
The pleasant surprises in the output that the artist says they would not have thought of but find inspiring are explained by Edward de Bono-style creativity theory. And contemporary art oeuvres tend to be materially random enough that the randomness of the works produced looks like moments in such an oeuvre. Where the production differs both from corporate big data approaches and contemporary artist-as-brand approaches is that production is not outsourced. Lund makes the art that they use data to specify.

Later, the Huffington Post article mentions the difficulty of targeting specific artists. A Hirst artwork specification generator would be easy enough to create for artworks that resemble his existing oeuvre. Text generators powered by markov chains were used as a tool for parodying Usenet trolls, and their strength lies in the predictability of the obsessed. Likewise postmodern buzzword generators and paper title generators parody the idees fixes of humanities culture.
The output of such systems resembles the examples that they are derived from. Pivoting to a new stage in an artist’s career is something that would require a different approach. It’s possible to move, logically, to conceptual opposites using Douglas Hofstadter’s approaches. In the case of Hirst, cheap and common everyday materials (office equipment) become expensive and exclusive ones (diamonds) and the animal remains become human ones.

This principle reaches its cliometric zenith in Colin Martindale’s book “The Clockwork Muse: The Predictability of Artistic Change”. It’s tempting to dismiss the idea that artistic change occurs in regular cycles as the aesthetic equivalent of Kondratieff Waves as Krondatieff Waves are dismissed by mainstream economics. But proponents of both theories claim empirical backing for their observations.
In contrast to The Fear Of Missing Out’s private database and the proprietary APIs of art market sites there is a move towards Free (as in freedom) or Open Data for art institutions. The Europeana project to release metadata for European cultural collections as linked open data has successfully released data from over 2000 institutions across the EU. The Getty Foundation has put British institutions that jealously guard their nebulously copyrighted photographs of old art to shame by releasing almost 5000 images freely. And most recently the Tate gallery in the UK has released its collection metadata under the free (as in freedom) CC0 license.

Shardcore’s “Machine Imagined Artworks” (2013) uses the Tate collection metadata to make descriptions of possible artworks. Compared to the data-driven approach of The Fear Of Missing Out, Machine Imagined Artworks is a more traditional generative program using unconstrained randomness to choose its materials from within the constrained conceptual space of the Tate data’s material and subjects ontologies.
Randomness is ubiquitous but often frowned upon in generative art circles. It gives good results but lacks intention or direction. Finding more complex choice methods is often a matter of rapidly diminishing returns, though. And Machine Imagined Artworks makes the status of each generated piece as a set of co-ordinates in conceptual space explicit by numbering it as one of the 88,577,208,667,721,179,117,706,090,119,168 possible artworks that can be generated from the Tate data.
Machine Imagined Artworks describes the formal, intentional and critical schema of an artwork. This reflects the demands placed on contemporary art and artists to fit the ideology both of the artworld and of academia as captured in the structure of the Tate’s metadata. It makes a complete description of an artwork under such a view. The extent to which such a description seems incomplete is the extent to which it is critical of that view.
We could use the output of Machine Imagined Artworks to choose 3D models from Thingiverse to mash-up. Automating this would remove human artists from the creative process, allowing the machines to take their jobs as well. The creepy fetishization of art objects as quasi-subjects rather than human communication falls apart here. There is no there there in such a project, no agency for the producer or the artwork to have. It’s the uncanny of the new aesthetic.
Software that directs or displaces an artist operationalises (if we must) their skills or (more realistically) replaces their labour, making them partially or wholly redundant. Dealing in this software while maintaining a position as an artist represents this crisis but does not embody it as the artist is still employed as an artist. Even when the robots take artists jobs, art critics will still have work to do, unless software can replace them as well.

There is a web site of markov chain-generated texts in the style of the Art & Language collective’s critical writing at http://artandlanguage.co.uk/, presumably as a parody of their distinctive verbal style. Art & Language’s painting “Gustave Courbet’s ‘Burial at Ornans’ Expressing…” (1981) illustrates some of the problems that arbitrary assemblage of material and conceptual materials cause and the limitations both of artistic intent and critical knowledge. The markov chain-written texts in their style suffer from the weakness of such approaches. Meaning and syntax evaporate as you read past the first few words. The critic still has a job.

Or do they? Algorithmic criticism also has a history that goes back several decades, to Gips and Stiny’s book “Algorithmic Aesthetics” (1978). It is currently a hot topic in the Digital Humanities, for example with Stephen Ramsay’s book “Reading Machines: Toward an Algorithmic Criticism” (2011). The achievements covered by each book are modest, but demonstrate the possibility of algorithmic critique. The problem with algorithmic critique is that it may not share our aesthetics, as the ST5 antenna shows.

Shardcore’s “Cut Up Magazine” (2012) is a generative critic that uses a similar strategy to “The Fear Of Missing Out”. It assembles reviews from snippets of a database of existing reviews using scraped human generated data about the band such as their name, genre, and most popular songs. Generating the language of critique in this way is subtly critical of its status and effect for both its producers and consumers. The language of critique is predictable, and the authority granted to critics by their audience accords a certain status to that language. Taken from and returned to fanzines, Cut Up Magazine makes the relationship between the truth of critique, its form, and its status visible to critique.
We can use The Fear Of Missing Out-style big data approaches to create critique that has a stronger semantic relationship to its subject matter. First we scrape an art review blog to populate a database of text and images. Next we train an image classifier (a piece of software that tells you whether, for example, an image contains a Soviet tank or a cancer cell or not) and a text search engine on this database. Then we use sentiment analysis software (the kind of system that tells airlines whether tweets about them are broadly positive or negative) to generate a score of one to five stars for each review and store this in the database.
We can now use this database to find the artworks that are most similar in appearance and description to those that have already been reviewed. This allows us to generate a critical comment about them and assign them a score. Given publishing fashion we can then make a list of the results. The machines can take the critic’s job as well, as I have previously argued.
What pieces like The Fear Of Missing Out and Machine Imagined Artworks make visible is an aspect of How Things Are Done Now and how this affects everyone, regardless of the nature of their work. This is “big data being used to guide the organization”. To regard such projects simply as parody or as play acting is to take a literary approach to art. But art doesn’t need to resolve such ontological questions in order to function, and may provide stronger affordances to thought if it doesn’t. What’s interesting is both how much such an approach misses and how much it does capture. As ever, art both reveals and symbolically resolves the aporia of (in this case the Californian) ideology.
The text of this review is licenced under the Creative Commons BY-SA 3.0 Licence.
Featured image: Still from performance of Structure M-11
You would measure time the measureless and the immeasurable.
You would adjust your conduct and even direct the course of your spirit according to hours and seasons. Of time you would make a stream upon whose bank you would sit and watch its flowing. – Kahlil Gibran
Algorithms only really come alive in the temporal time-frames that they move through. Their existence depends on being able to move freely along time’s arrow, unfolding and expanding out in to the universe, or reversing themselves backwards into a finite point. Every form and structure that the universe creates is the result of a single step along that pathway and we’re only ever observing it at a single moment. Those geological steps can take millions of years to unfold and we can only ever really look back and see the steps that happened before we chose to observe them. Computational algorithms break down that slow dripping of nature’s possibilities and allow us to become time-travellers, stepping into any point that we choose to.
Paul Prudence is a performer and installation artist who works with computational, algorithmic and generative environments, developing ways to reflect his interest in patterns, nature and the mid-way point between scientific research and artistic pursuit. The outputs from this research are near cinematic, audio-visual events. Prudence’s creative work, and his blog, Dataisnature (kept since October 2004), explores a number of creative potentials as well as documentating the creative and scientific research work of others that he finds of interest. As the blog’s bio states:
“Dataisnature’s interest in process is far and wide reaching – it may also include posts on visual music, parametric architecture, computational archaeology, psychogeography and cartography, experimental musical notational, utopian constructs, visionary divination systems and counter cultural systems.”
Paul himself feels Dataisnature, and his other blogs, are by their very nature ordering systems, trying to create some kind of structure on information. “Yes, it’s true [that they are ordering systems], but the ordering is sometimes a little bit oblique. I am not interested in ordering systems such as categories or tags, for example, as each blog post has the potential to generate many of its own categories.”
The blog and perhaps all blogs, shouldn’t be an end in themselves then? Should they be a starting point for a deeper investigation? “Well, I’m more interested in substrate and sedimentary structuring – specific fields existing in layers and sometimes overlapping and interacting rhizomatically.”
Blogging for Paul and many bloggers who don’t operate within the ‘monetization of blogging’ sphere that has grown up in the past few years could almost be considered a documentation and ordering process for the creative process. The process and interaction between the theory and the blog as textual artefact becomes quite complex. As does the theory and creative output of the blogger. Paul would argue that this isn’t always something that can be even as straightforward as theory to practice though.
“The posts at Dataisnature are not confined to theoretical relationships between art and science projects, but also take into account metaphorical ones. I never wanted the posts to be so pinned down that they disable the opportunity to make entirely new connections at any level.”
So the chance to see what happens inbetween strict disciplines and an openness to the potentials that may arise out of relaxing the barriers? Shouldn’t that be the way that everything else that is ‘not of academia’ operates anyway? And for that matter, outside of the possibilities of arts/science/research funding.
“I applied the term ‘recreational research’ to Dataisnature in its early days,” Paul explains. “This is still to some degree important – the notion that research doesn’t have to be tied down by the prospect of peer review or academic formatting. This kind of interdisciplinary research can be highly addictive – its the new sport of the internet age. It can generate blogs that become chaotic repositories of interconnectedness – linearity becomes infected with cut-up and collage. In my own mind I have an idea of what Dataisnature is trying to say but I get people approaching me with completely different, and amusing theories of what they believe the blog is about.”
In digital arts (or let us call it digital creativity, to avoid the complexity of art versus design versus technology) the breakdown between the equipment used and the research of the creator has become almost at times indistinguishable. A painter is often only one step away from being a chemist, a sculptor closer to an engineer than a painter. The tools used define and form some of the output. Digital creativity only makes this more implicit. So when using technologies and researching, the scientist and the creative often walk hand-in-hand towards the finished artefact. As Prudence says: “Collaboration among artists and scientists exists through time as well as space.”
“A great part of an artist’s task is to be a researcher. It’s important to remember that any idea you have has already been tackled in the past with a different (want to avoid the term lesser) technology.”
The blogging process offers a chance to gather information and allow some of the artist’s own influences and present interests to manifest themselves into a rough-hewn structure. “For me, blogging facilitates a medium for an archaeology of aesthetics, technology and conceptuality. All this fragmented information is gathered then reconstituted, and fed back into the artistic practice. Of course my personal work blog is more about supplying supplementary material to anyone interested in my work.”
Taking an arguably typical example of Paul Prudence’s work, for example Structure-M11, the sense of a becoming and developing is in the way it attempts to reconnect with what (for want of a better phrase) could possibly be called our lost industrial heritage.
Looking through Prudence’s flickr stream documenting the research trip, there are numerous industrial landscapes empty of human life, where only the machines have been allowed to remain, static and poised, ready to begin work again. If only someone would employ them. These machines perform simple tasks, but they do it elegantly, time after time after time, never complaining and never asking for any recognition. Perhaps that’s why it is so easy to abandon them? And these machines are not only a monument to the way we discard unwanted technologies, they also reflect the changing fortunes of the town as it has moved from production-based economy to one centred mainly on tourism and smaller businesses. It is fitting in a way that the soundscapes and visuals that Prudence has brought to life from these landscapes have such a contemporary, sci-fi industrial feel to them. As though the clean, slick lines and geometric perfection had emerged, phoenix-like, from the unbearably hot, oil soaked environments of the factories and the monotonous repetition of working within them.

The soundtrack that accompanies the performance was made from field recordings at the site. From these, Prudence generated real-time visuals that reflected some of the sonic activations and echoes throughout these landscapes. The final pieces look like ‘robotic origami contraptions.’ The steady throb and crash of the audio reflects the repetition of the machine and its operator’s lives while also suggesting some of the dehumanising effects working in a factory can have on a person. There’s also the beauty, of course, if you shift your own perception a few degrees away from the machines, there is always a window looking out at a natural landscape. And those same slick, geometric shapes of the machines begin to reflect some of the elegance of the world of nature. Nature, like humanity, loves to repeat itself infinitely until something breaks that pattern. Isn’t that a fundamental part of mutation and evolution? Structure-M11 seems to be constantly mutating and growing new rhizomes, but nothing complete ever emerges. Paul Prudence’s work isn’t here to save us from the monotony of the machines though, its task is to remind us of how important nature is to our lives, no matter how entangled in the machine those lives may begin to feel.
Prudence’s interest in the natural spaces emerges from his own theory-based interests. As he says, “My interest in generative systems and procedural-based methodologies in art lead to a way of seeing landscape formations and geological artefacts as a result of ‘earth-based’ computations.”
“The pattern recognition part of the brain draws analogies between spatio-temporal systems found in nature and ones found in computational domains – they share similar patterns. I began to think of the forms found in natural spaces more and more in terms of the aeolian protocols, metamorphic algorithms and hydrodynamic computations that created them.”
“Some of these pan-computational routines run their course over millions of years, some are over in a microsecond, yet the patterns generated can be amazingly similar. I like the fact that when I go walking in mountains my mind switches to [the] subject of process, computation and doWhile() loops inspired by the geological formations I come across.”
This connection and flowing from one space to the other, gives the viewer the feeling that they recognise the shapes and patterns from something they’ve seen before. Attending a performance of Prudence’s work might make you feel as though you’ve been to one already. But it’s just the reconnection of interconnection that you’d be experiencing. And that’s always a good place to start, when experiencing any artwork, isn’t it?
21 Sept 2012
Scopitone Festival, Nantes, France.
24 Sept 2012
Immerge @ SHO-ZYG, London
17-25 October 2012
VVVV Visual Music Workshops at at Playgrounds 2012, National Taipei University of Art, Taipei & National Museum of Art, Taichung, Taiwan
Prank sombody with the fake Windows 10 upgrade screen which never ends. Open the site in a web browser and go full screen with the F11 key.
